I. INSTRUCCIONES PARA LA FABRICACIÓN DE PARTES: LA MOLÉCULA DEL ADN
EL MOVIMIENTO de las células, igual que sus demás funciones, es como el de una maquinaria integrada por muchas piezas que deben funcionar con precisión. A diferencia de las máquinas construidas por el hombre, la célula tiene que fabricar todas y cada una de sus partes y ensamblarlas después en un conjunto funcional. En gran medida el ensamblaje de las partes procede de manera automática gracias a que las piezas tienen formas definidas y complementarias que encajan unas con otras como en un rompecabezas. Por consiguiente, la funcionalidad del conjunto depende de la precisión en la fabricación de las partes, lo cual asegura el engranaje perfecto. La célula cuenta con los planos o instrucciones para fabricar estas piezas en un código almacenado en las moléculas de ácido desoxirribonucleico (ADN), el cual se encuentra contenido dentro del núcleo en la mayoría de las células. Estas instrucciones son muy importantes y necesarias para el correcto funcionamiento de cada ser vivo, por lo que deben preservarse cuidadosamente y ser transmitidas de generación en generación, ya que constituyen el material genético.
Una molécula de ADN tiene una estructura helicoidal, parecida
a una escalera de caracol que gira hacia la derecha y en la que los escalones
están formados por un par de moléculas planas unidas entre si por puentes angostos,
llamados puentes de hidrógeno, unidas a la vez, como los eslabones de una cadena,
a las moléculas que forman los escalones contiguos a través de uniones químicas
covalentes denominadas enlaces fosfodiester. Las moléculas planas de los escalones
son bases nitrogenadas de cuatro variedades, adenina, guanina, citosina y timina
y se representan como A, G, C y T. Debido a sus formas y dimensiones particulares
cada base del par, o sea un medio escalón, sólo puede hacer pareja con otra
base especial para completar el escalón. Así tenemos que A se aparea solamente
con T, y G solamente con C, lo que da como resultado que las bases de un escalón
sean siempre complementarias. Los escalones son distintos entre sí y pueden
estar ordenados en una gran diversidad de secuencias, tantas como las combinaciones
posibles en el alfabeto que maneja la célula, que es de cuatro letras, A, T,
G, C. La conexión, entre las bases de una misma cadena se hace por enlaces que
se establecen entre las moléculas del azúcar des oxirribosa que acompaña cada
una de las bases y grupos fosfato asociados a los oxidrilos de las desoxirribosas
(Figura I.1).
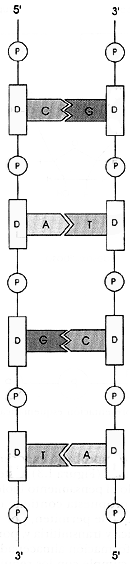
Figura I.1. Organización de las bases en las cadenas de la doble hélice
del ADN. A = adenina, T = timina, G = guanina, C = citosina, D
= azúcar desoxirribosa, P = enlace fosfodiéster.
Al conjunto que forman una base, su azúcar y uno o más fosfatos se le llama
un nucleótido. Será un nucleótido monofosfato si tiene un fosfato, nucleótido
difosfato si tiene dos, etc. En la molécula del ADN un fosfato
une a dos nucleótidos formando el enlace fosfodiester (Figura I.2). Una secuencia
definida de pares de bases constituye lo que se llama un gen, la variabilidad
en la secuencia de bases forma el código genético. En los genes de un organismo
está la información precisa, que al ser descifrada permite construir las piezas
necesarias para que funcionen las diferentes máquinas que en su conjunto forman
una célula. El núcleo de pares de bases y de genes en un organismo puede ser
muy variable. El ADN de un virus tiene alrededor de 5 000 pares
de bases, mientras que el ADN humano 4 500 millones.
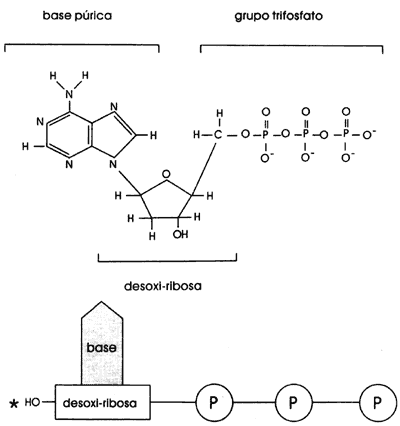
Figura I.2. Fórmula y representación esquematica de los nucleótidos trifosfato.
En 1953, James Watson y Francis Crick, trabajando juntos en Inglaterra; y basándose
en estudios de otros investigadores, como Linus Pauling, Rosalind Franklin y
Maurice Wilkins, concibieron un modelo de la estructura del ADN
que reunía todos los requisitos de una molécula autorreplicable. Este modelo
es conocido como el modelo de la doble hélice y corresponde a la forma como
se ha comprobado experimentalmente que se arreglan estas moléculas (Figura I.3).
Este modelo tuvo gran repercusión sobre todo el pensamiento biológico del momento,
ya que la estructura propuesta contiene dentro de sí misma todos los elementos
que le permiten, por un lado, almacenar la información genética y transmitirla
y, por el otro, duplicarla, asegurando que la información almacenada pase a
otras generaciones, con lo cual cumple con los requisitos para ser un almacén
de información tan importante.
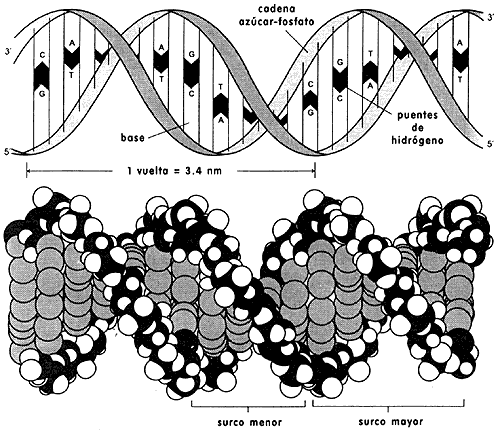
Figura I.3. Imagen tridimensional de la doble hélice.
Una mólécula de ADN que contiene miles de pares de bases puede
tener longitudes macroscópicas, es decir, que se podrían medir con una regla
y hasta con un metro. El ADN de la bacteria Escherichia coli
por ejemplo, tendría 1 mm de longitud, o sea 1 000 veces más largo que la longitud
total de la bacteria. Para caber dentro de esta célula el ADN tiene
que ser compactado, como sucedería al rehacerse un ovillo de estambre que se
ha desmadejado. En los organismos eucariontes, llamados así porque sus células
contienen un núcleo, el ADN no está en el citoplasma, como en las
bacterias, sino dentro del núcleo, el cual a su vez está contenido dentro de
la célula y por consiguiente es muy pequeño. En este caso la molécula de ADN,
cuya longitud es mayor que el ADN de las bacterias, tiene que compactarse
muchísimo y esto se logra enredándose sobre otras moléculas, que son las proteínas
llamadas histonas. Se forma así la unidad básica de las estructuras conocidas
como cromosomas y de las cuales todos los organismos mantienen un número constante.
La longitud del ADN cuando se empaca en un núcleo se reduce de
1.5 m para formar cromosomas cuya longitud promedio es de 1 x 10-6m
(Figura I.4).
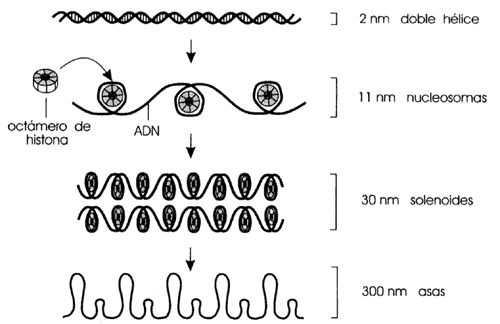

Figura I.4. Los estados de comparación de la cromatina para formar un cromosoma.
Independientemente de la forma en que el ADN se compacte, la información genética está siempre contenida en la estructura primaria de la doble hélice. Al ser complementarios todos los pares de bases, la clave escrita en la secuencia de bases en una de las cadenas de la hélice, correspondiente a la mitad de los escalones, será el molde de la otra mitad. Una analogía a esta situación sería lo que es el positivo y el negativo en una película fotográfica, que tienen la misma imagen pero complementaria. La clave se puede ir descifrando en cualquiera de las dos cadenas pero leyéndola en sentidos opuestos, como puede verse en la Figura I.1. Por esta razón se dice que una molécula de ADN tiene polaridad. Cada cadena tiene entonces un extremo 5´ y uno 3´ en lados opuestos. Por la polaridad y complementaridad del arreglo de las bases siempre se puede reconstruir un medio escalón, ya que se sabe qué base se necesita para completarlo, y si se daña una de las cadenas, ya sea en su totalidad o solamente en un fragmento, este daño podrá repararse copiando de la cadena intacta (que será el molde) la secuencia dañada. Esta reparación restituye así la información completa.
Ya que la información genética tiene que transmitirse de generación en generación,
las moléculas del ADN deben duplicarse muchas veces, tantas como
una célula se divida para formar dos nuevas células y debe hacerlo con alta
fidelidad. ¿Cómo puede entonces duplicarse una molécula tan grande y compleja?
La replicación del ADN requiere a su vez de la duplicación de cada
una de las cadenas por separado, lo cual se puede hacer si en principio las
dos cadenas de la hélice se separan (Figura I.5). Abrir todos los puentes que
unen a los pares de bases de cada escalón requiere gran cantidad de energía,
esto y la formación o síntesis de las nuevas cadenas necesita la participación
de otras moléculas que proporcionen la energía, y que como ayudantes mantengan
abiertas a las cadenas maternas para que los nucleótidos puedan ser adicionados
a las cadenas nuevas. Estas moléculas ayudantes son las proteínas llamadas enzimas,
las cuales pueden actuar como catalizadores de reacciones químicas. Se unen
a las moléculas que participan en la reacción, llamadas substrato, aumentando
su concentración local en el sitio en donde se llevará a cabo la reacción y
manteniendo la orientación correcta de los grupos químicos reaccionantes. Además,
al unirse al substrato, la energía derivada de esta unión contribuye a la catálisis.
Al final de la reacción la enzima se desprende del substrato ya modificado,
quedando lista para actuar de nuevo. El proceso de replicación de una molécula
del ADN demanda alta fidelidad y podría dividirse en tres grandes
etapas. La primera es la selección del nucleótido que se va a incorporar a la
molécula nueva y el desenrollamiento de las cadenas en el sitio en donde va
a empezar la replicación y se incorporan los nucleótidos seleccionados.
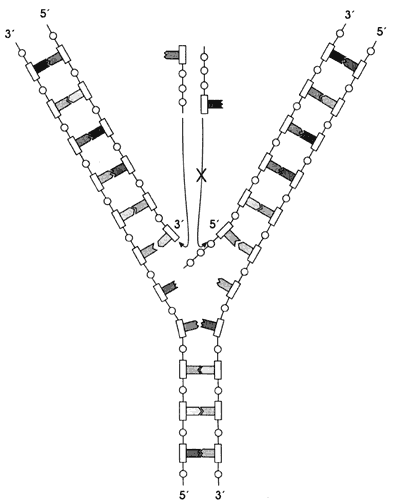
Figura I.5. Replicación del ADN. El crecimiento en la dirección
5´- 3´ es el que sucede en forma continua. No se ha encontrado ninguna polimerasa
que pueda agregar nucleótidos en la dirección 3´- 5´.
Una vez incorporado un nucleótido a la nueva cadena, hay que asegurarse que es el correcto, es decir, el complementario a la base o letra que se está leyendo en la cadena que sirve de molde. Un error en esta parte implica que el nucleótido tendrá que ser eliminado, pues de lo contrario el código se altera y al descifrarlo se tendrá una palabra incorrecta y una instrucción errónea. Finalmente, una vez terminado el ensamble de los nuevos nucleótidos en una cadena hay que asegurarse de la fidelidad de la copia y hacer las correcciones necesarias, como un editor al revisar un texto recién escrito o impreso.
La enzima llamada polimerasa del ADN es la que se encarga de seleccionar el nucleótido adecuado y meterlo a la cadena que se está construyendo. Los nucleótidos se incorporan al ADN como nucleótidos trifosfato, se pegan entre sí formando el enlace químico llamado fosfodiéster, perdiendo dos grupos fosfato.
El apareamiento correcto ya mencionado, y que solamente se da entre bases complementarias, A con T y C con G, es aparentemente la forma más estable desde el punto de vista energético. Sin embargo, se ha calculado que se introduce un nucleótido que no corresponde por cada 10 millones de pares de bases; este nucleótido es sacado de la cadena al romperse su enlace fosfodiéster por otra enzima llamada exonucleasa.
En algunos casos se pasa por alto el error y esto puede resultar en un beneficio para el organismo, ya que el futuro de una población depende en parte de su habilidad para cambiar y adaptarse fabricando piezas de máquinaria con ciertas ventajas para una nueva situación. Estos cambios o mutaciones suceden frecuentemente cuando las condiciones del medio ambiente se hacen más difíciles. Tal posibilidad de cambio y adaptación, iniciada en las secuencias de las bases del ADN, constituye la base molecular del proceso evolutivo de las especies conocido como selección natural.
La polimerasa únicamente puede incorporar los nucleótidos en una de las dos
cadenas a la vez, pues lo hace leyendo el mensaje que está en la cadena que
tiene la orientación 3´-5´s. ¿Cómo se hace entonces la síntesis de la otra cadena
que tiene la polaridad invertida? El proceso es un poco diferente y la copia
de esta cadena se hace ensamblando pequeños fragmentos sobre las bases que llevan
la orientación correcta 3´-5´, aunque por esta razón la incorporación de nucleótidos
no puede ser continua. Estos fragmentos son sintetizados después de un iniciador
formado por ribonucleótidos del ácido ribonucleico (ARN) y se denominan
fragmentos de Okazaki (su descubridor), y están unidos o ligados por una enzima
llamada ligasa, previo desprendimiento del ARN iniciador. La fabricación
o sin tesis de esta cadena es más lenta, ya que implica la participación de
varias enzimas y un mecanismo más complejo (Figura I.6).
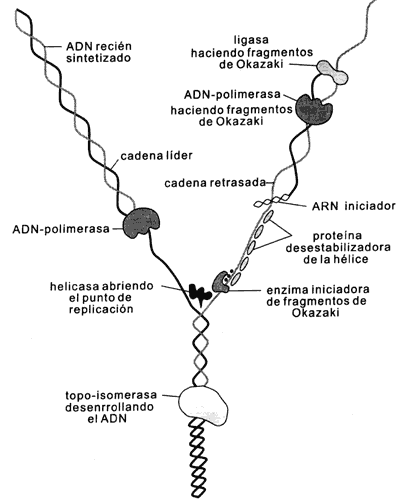
Figura I.6. Ilustración de un punto de replicación en la doble hélice.
Se muestran las varias enzimas que participan.
La síntesis de nuevas cadenas del ADN también requiere del desenrollamiento
de la doble hélice en el punto de replicación para que puedan; llevarse a cabo
todas las acciones de incorporación de nuevos: nucleótidos. Esto se realiza
mediante enzimas específicas que facilitan el proceso, como las llamadas topoisomerasas,
B helicasa, etc., que ayudan a desenrollar la doble hélice y a mantener las
dos cadenas separadas mientras se incorporan los nucleotidos. Estos procesos
necesitan de la energía que es provista por el ATP. En el caso
de que el ADN se asocie a proteínas, como sucede en los organismos
nucleados, la replicación del ADN va acompañada por la síntesis
de estas proteínas, ya que la nueva molécula del ADN debe enrollarse
nuevamente sobre ellas para formar los cromosomas.
Entendiendo la estructura de la doble hélice, ¿podremos conocer la secuencia en que se ordenan las bases para formar genes en una determinada molécula de ADN? Cada célula humana, por ejemplo, contiene aproximadamente 100 000 genes, cuya información, al ser descifrada, permite formar un ser humano funcional. Esta información contenida en el ADN de cada organismo constituye su genoma. Descifrar la estructura de los genes de: un genoma, aunque éste corresponda a un organismo primitivo o tan complejo como un ser humano, es una tarea de grandes proporciones, ya que hablamos de millones de pares de bases. Sin embargo, las nuevas técnicas desarrolladas para el estudio del ADN hacen posible pensar que en un futuro próximo se podrá tener descifrado el genoma humano. Ya se han localizado 1 500 de los genes humanos en varios de los 23 pares de cromosomas que forman el mapa cromosómico humano. Una de las técnicas más promisorias en la tarea de identificar genes es la posibilidad de introducir y multiplicar, dentro de las bacterias, fragmentos del ADN de cualquier organismo.
Esta multiplicación de fragmentos específicos, llamada donación, permite que el ADN introducido (extraño) se replique y amplifique en las bacterias, las cuales al crecer y multiplicarse producen cantidades grandes de los fragmentos del ADN extraño. Si se logra obtener un número grande de bacterias recombinantes (aquellas que han integrado fragmentos del ADN extraño) , la posibilidad de tener donados a la mayoría de los genes contenidos en el ADN de cualquier organismo es también muy alta. Se tiene así lo que se llama una biblioteca genómica, ya que de ésta podrá sacarse en cualquier momento la información guardada junto con el ADN de las bacterias. Los diferentes genes presentes en una biblioteca de este tipo pueden identificarse; por varias metodologías que se han desarrollado en los últimos años y que por su importancia en la investigación biológica les ha merecido a sus inventores el codiciado premio Nobel. Una vez identificado el gen, su secuencia de nucleótidos se establece caracterizando a las bases que la forman por sus propiedades químicas y físicas. En este punto ha sido muy importante el descubrimiento de enzimas que pueden romper las cadenas del ADN en sitios en donde hay una secuencia particular de bases, como sería por ejemplo AGTC. Al usar la enzima que solamente rompe a esta secuencia sabemos de antemano que si se rompe el ADN que estamos estudiando es porque existe esta secuencia en el gen. El uso de una combinación de este tipo de enzimas facilita no sólo la identificación de las bases sino que nos permite conocer su arreglo lineal en una molécula de ADN.
Con estas metodologías se ha podido conocer la secuencia de varios genes y establecer que no todos sus nucleótidos contienen la información utilizable para construir las partes de la maquinaria. Estas secuencias, sin información, tienen una función regulatoria, necesaria para que pueda descifrarse la clave de un gen, asegurando, a través de programas bien establecidos, cuándo y como se va a transmitir la información contenida en el gen. Hay también algunas secuencias en el ADN que no contienen ningún mensaje pero cuyo papel regulatorio se ejerce cuando la molécula del ADN se va a duplicar, cuando se desenrolla y vuelve a enrollarse para formar los cromosomas o también cuando se desenreda un poco mientras se pasa la información del código a otras moléculas encargadas de llevar las instrucciones a los sitios donde se fabrican piezas para las máquinas celulares.