En la dicotomía entre el punto de vista poético y el punto de vista lógico del lenguaje, este último tiene ya siglos de llevar la iniciativa, pues nos hemos alejado constantemente de la cultura oral de Grecia y Roma y de la Europa Medieval. Esto no significa que no hayamos tenido grandes poetas, sino más bien que la nuestra no es una era de poesía. Inclusive en plena Edad Media no faltaron quienes (los filósofos nominalista) sostuvieron que los nombres son simplemente cuestiones convencionales. Ese argumento cobró más fuerza persuasiva después de la invención de la imprenta de la revolución matemática que llevaron a la lectura en silencio y a la manipulación de símbolos asignados de un modo convencional. Con el advenimiento de la computadora, la lógica sigue triunfando sobre la poesía. Todo el curso de la filosofía lingüística desde Leibniz a los positivistas parece culminar en la computadora, donde a los símbolos se les quitan connotaciones y se les da significado sólo por medio de una definición inicial y de relaciones sintácticas con otros símbolos.
El credo positivista pertenece a la edad de la imprenta, no a la de la computadora. Podríamos muy bien preguntarnos si los antiguos filósofos lingüistas se sentirían satisfechos o quizá un poco fuera de lugar por la amplitud con que la computadora ha dado realidad a su visión de un modo de comunicación totalmente lógico, pues es un hecho de que la computadora lleva sus ideas a un extremo impensable en la época anterior. Con sus páginas uniformemente impresas, la prensa sugirió que las palabras eran simples signos que debían ser manipulados por los ojos y la inteligencia del lector. Más todavía las palabras se quedaban fijas el la página impresa y exigían un esfuerzo mental considerable por parte del lector. Leer es trabajo, hecho que con frecuencia olvidan los educadores que se preguntan por qué los niños prefieren la televisión a los libros. El misterio de la mente no se pudo eliminar del trabajo de leer mientras el "procesador de palabras" real siguiera siendo el individuo que abría el libro y lo hojeaba.
La prensa es un mecanismo rígido que sólo puede repetir el mismo producto,
páginas, cuyas líneas tienen un orden que ha sido fijado de una vez por todas
y para siempre por el impresor. En cambio, la computadora que altera su forma
y su propósito lógico conforme marcha, escapa a la rigidez de la producción
mecánica de las palabras. Ya las palabras no se quedan sobre el papel; se abren
paso por entre la unidad de memoria y de procesamiento. Ya no necesita inteligencia
humana para manipular símbolos verbales; tal cosa la hace la computadora siguiendo
un programa, de forma muy parecida al del compilador que lee y traduce en iniciados
en FORTRAN sin que intervenga ningún humano. Ahora bien, aquí no
operan procesos mentales misteriosos, como los que siempre hubo tratándose de
los libros. En que la computadora haya eliminado a la mente del acto de leer
es un cambio pasmoso. Mientras hubo mentes que participaran en el "procesamiento"
de un lenguaje, fue difícil tratar al lenguaje sólo como un conjunto de símbolos
arbitrarios. Por su propia naturaleza la memoria humana es resonante, establecen
asociaciones de palabras que desafían la lógica, da a las palabras connotaciones
que van más allá de su definición, traza analogías entre el mundo exterior y
las palabras que lo representan. Con palabras y símbolos fijados en páginas,
hasta los lógicos tienen que atenerse a su memoria y a su facultad de razonamiento
para poner en movimiento a los símbolos. Ahora bien, cuando la computadora los
pone en movimiento en lugar de él, no hay posibilidad de que la resonancia o
analogía se inmiscuyan con las reglas de la lógica.
El lenguaje de la computadora, es, como los lógicos había esperado, el triunfo de la estructura sobre el contenido; para ser más precisos, es una reinterpretación del contenido (de los que los lingüistas llaman "semántica") en términos de estructura. Nunca tuvo el lenguaje fuera del estudio del lógico tal claridad estructural, tal pureza de formas. Y nunca antes el punto de vista lógico del lenguaje halló aplicación en tal variedad de tareas prácticas. En cierto sentido, cada nuevo problema programado en la máquina —cada nuevo compilador, sistema de recuperación (retrieval) de información para negocios o ciencia, cada procesador secretarial de palabras— es una nueva conquista del punto de vista lógico del lenguaje.
Nada tiene de extraño que en nuestra edad los lingüistas estén empezando a ver el lenguaje de un modo muy similar a como los especialistas en computación ven a sus cifrados o códigos. Empezamos destacando las diferencias entre lenguaje natural y cifrados de computación, pero para muchos las similitudes parecen ser hoy día de mayor significación. La lingüística moderna es, no hay duda, un vástago de la computadora; más bien, tanto la lingüística como el lenguaje de la computadora son hijos de su época, que se esfuerzan sinergéticamente para cambiar la mismísima cultura que les dio vida. El trabajo empezó con los lingüistas estructurales de los años 1940 y 1950 que analizaron jerárquicamente el idioma inglés (de palabras-a-frases-a-cláusulas) y mediante procedimientos mecánicos esperaron eliminar por completo el problema del significado. Así las cosas, en 1957 apareció la obra de Noam Chomsky titulada Syntactic Structures (fue el mismo año en que se dio a conocer FORTRAN), obra en la cual se propuso la gramática "generativa transformacional". El enfoque de Chomsky y de otros ha influido muchísimo en el mundo de habla inglesa.
El nuevo enfoque consiste en considerar el lenguaje como una estructura algebraica
más que como un lexicón de palabras individuales. De manera aislada, un nombre
tiene poco interés; lo que importa es la forma en que nombres, verbos y otras
partes de la oración se puede unir para "generar" frases. La "maña" consiste
en identificar reglas que permitan producir frases legítimas y en usar estas
reglas para describir la mayor cantidad posible del idioma inglés. Estas reglas
se suelen escribir en símbolos abstractos y en ocasiones se parecen mucho a
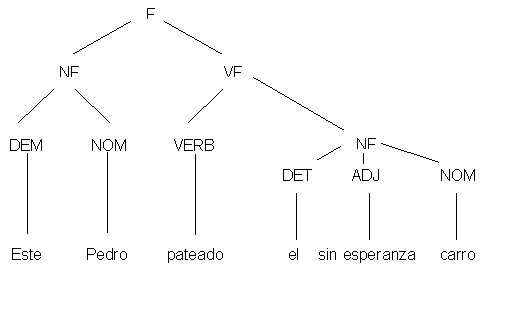
la lógica simbólica. Un plan muy popular es atribuir una estructura arbórea
a cada frase. En la parte superior se escribe un solo símbolo, S, que abarca
toda la frase. En cada nivel inferior se describe la estructura con más detalles
hasta que las palabras de la frase aparecen como hojas de árbol. Cada nivel
es generado por el que está arriba de él, mediante reglas tales como F=NF
VF que indica que el símbolo F tiene dos descendientes, NP
y VP, y que en términos gramaticales anticuados significa que cada
frase (F) se compone de un sujeto (nombre frase = NF) y
de un predicado (verbo frase =VF). Esta gramática es prolífica
porque podemos usar sus reglas para generar frases (o al revés para analizarlas).
Igualmente importante es la idea de que una estructura gramatical puede ser
transformada en otra sin que intervenga un cambio de significado. Por ejemplo,
una frase en voz pasiva, "Juan fue electrocutado por el procesador central",
se transforma en la voz activa "el procesador central electrocutó a Juan".
Es interesante observar cuán estrechamente estas manipulaciones algebraicas del lenguaje natural concuerdan con las manipulaciones de la computadora en sus códigos. Los lingüistas trazan tres diagramas para analizar frases del mismo modo que los compiladores los crean para procesar enunciados en FORTRAN. Al igual que FORTRAN, el español lingüista es una hilera de símbolos, todos los cuales carecen de contenido mientras no se les defina y todos ellos guardan una relación ordenada con respecto a otros símbolos de la hilera. Al igual que ocurre en FORTRAN, el procesamiento del español es la transformación de una forma (una hilera de palabras) a otra (un diagrama-árbol) o de regreso, conforme a una serie de normas de sustitución. Las computadoras transforman los enunciados de input en output, del mismo modo que la gramática de los lingüistas transforma la voz activa en pasiva. Hoy día los especialistas en computación admiten de muy buen grado la influencia que ha tenido la lingüística reciente en sus esfuerzos prácticos y teóricos. Y a la inversa, sus lenguajes de computación son los únicos que se describen perfectamente por medio de estas reglas generativas; lenguajes naturales complejos e irregulares han resultado menos apropiados al enfoque algebraico.
En la computadora se pueden programar ejercicios simples para generar español.
En realidad, programas así se han convertido en tareas normales para principiantes.
Al programa se le da un vocabulario así como estructuras buenas y simples pero
legítimas para combinar vocabulario y formar frases. En seguida une palabras
por medio de selección al azar (random selection). En versión más simple
del programa no se imponen restricciones de significado: simplemente el programa
inserta cualquier nombre en un lugar apropiado para un sujeto u objeto, algún
verbo en una ranura que requiere acción, etc. Las frases resultantes son perfectas
sintácticamente y con frecuencia ridículas (gráfica VIII.2). También son, si
se leen una tras otra, extrañamente desconcertantes. Empieza uno por buscar
casi desesperadamente algún significado oculto en las pautas sintácticas y nuestra
risa se torna punto menos que nerviosa cuando la máquina que puede decir cualquier
cosa, dice algo profundo, inclusive embarazoso.
|
|
| Normas de producción para la generación automática de frases en español |
| ( " : = " indica que el símbolo situado a la izquierda es sustituido por la |
| hilera a la derecha, y "1" especifica versiones alternas de la misma regla). |
| F : = NF VF |
| NF : = ADJ DET NOM / DEM NOM |
| VF : = ADV VERV NF / VERB NF / VERB NF FF |
| NOMBRE : = Pedro / lámpara / Andrés / Natascha / Ana / castillo / carro |
| VERBO : = basados / seducido / pateado / abandonado / casado |
| DET : = el |
| DEM : = este / ese |
| ADJ : = locuaz / desventurado / despreciable / airado / esperanzado / sin esperanza |
| ADV : = rara vez / nunca |
| PREP : = de / con / en / sin |
| Muestra de frases generadas "al azar" |
| Una representación árbol de una frase generada de estas reglas : |
| 1. El esperanzado Andrés abandonó a la desventurada Ana en el airado carro. |
| 2. La despreciable lámpara abandonó a la locuaz Natascha con la airada Natascha. |
| 3. La airada Natascha casó con el sin esperanza carro arriba de la despreciable Ana. |
| 4. La airada Ana sedujo a la despreciable lámpara con el desventurado carro. |
| 5. Este Andrés casó con la desventurada lámpara. |
| 6. Este Pedro pateó al desventurado carro. |
| 7.Este castillo besó a la esperanzada Ana |
| 8. La locuaz Natascha casó con la locuaz Natascha. |
| Estas frases obedecen las normas estructurales del español, aunque casi siempre carecen de |
| sentido. Ejemplifican la capacidad de la computadora de separar estructura de significado. |
|
|
Esto nos trae de vuelta al problema del significado. Problemas del lenguaje se vuelven inmediatamente en problemas de conocimiento: cómo el lenguaje nos ayuda a conocer o, si se prefiere, dónde está el significado, en o atrás de nuestras palabras. El propio Chhomsky, perfectamente consciente de los problemas de más fuste que asoman atrás de su lingüística, ha dicho que el lenguaje es "un espejo de la mente"; ha llegado al extremo de definir a la mente como "la capacidad innata de formar estructuras cognoscitivas", estructuras que son "representadas de un modo todavía no conocido en el cerebro" (Reflections on Language, 4, 23). Un colega de Chomsky, Jerry Fodor, ha bordado sobre esta idea en una obra titulada Reflections on Language of Thought: que el lenguaje no es, por supuesto, ni inglés ni alemán, sino más bien una especie de código interno interconectado en nuestro cerebro desde nuestro nacimiento, un código preparado expresamente con el lenguaje de la computadora. Al pensar, transformamos mensajes en este código, desde estados iniciales, pasando por formas intermedias, hasta llegar al output, que puede ser verbal o muscular.
Nos bastará pensar un poco, contemplar unas cuantas transformaciones en nosotros para darnos cuenta de cuán lejos estamos de la idea de significado que fue común en las culturas anteriores. Antes del periodo parteaguas de la imprenta y de la física matemática, y sin duda bien adentro de esa era, el sonido, la presencia vívida de nombres y palabras individuales significaba algo por sí mismo. El acento recaía en los sustantivos como nombres, en tanto que la relación entre palabras en una frase era determinada principalmente por el modo en que sus significados chocaban y se combinaban. Pero en la era de la computadora se usan estructuras silentes espaciales para cartografiar el significado del lenguaje y, en estos casos, el significado de una frase es su estructura, que nuestra mente, como una computadora, puede representar, destilar y transformar, porque la mente en sí no es otra cosa que la capacidad de formar estructuras. No hay duda de que los lingüistas no han abandonado los problemas de semántica; ahora hablan del " lexicón" que los humanos llevan en la cabeza. De hecho las palabras de este lexicón son definidas por las relaciones que permiten. Así, "perro" es definido como palabra a la cual se aplican ciertos clasificadores (animado, animal, domestico, etc.); puede servir como sujeto de verbos tales como "morder", "correr" o "ladrar" pero no de "refutar", "aplaudir" o "votar".
Algunos prefieren definir "redes semánticas", en los cuales los nudos representan conceptos, acontecimientos, personas u objetos y los vínculos representan asociaciones entre estos conceptos. Esta definición convierte también la experiencia humana del significado de una estructura espacial, que puede ser representada gráficamente en el papel o almacenada en la memoria de una computadora. Los símbolos colocados en los nudos están esencialmente vacíos, no tienen resonancia o profundidad y en la máquina son marcas en el papel o bits. No se puede hacer nada con estos símbolos, excepto remontarlos, sumarlos o bien borrar vínculos entre ellos. Una noción menos tangible de significado carece por sí misma de significado para la computadora.
 |
 |
 |
 |
 |