III. AISLANDO GENES: CASOS DE LA VIDA REAL
HASTA el momento hemos descrito una serie de manipulaciones que
ocurren de manera muy simple. En las épocas pioneras del ADN recombinante,
la donación de cada nuevo gene resultaba ser un hecho importante. En este capítulo,
conforme se presentan ejemplos de aislamiento y caracterización de genes específicos,
iremos viendo cómo entran en juego los diferentes problemas que se requiere
resolver. Más interesante aún, es que podremos explorar las formas ingeniosas
y la gran cantidad de trabajo que se ha requerido para sortear estos problemas.
Actualmente, el aislamiento de ciertos genes es una tarea sencilla, casi rutinaria.
Específicamente, la relativa simplicidad de los genomas de bacterias presenta
pocas dificultades al arsenal de técnicas contemporáneas. El caso de un gene
humano, sin embargo, es una historia muy distinta. Un gene humano se encuentra
disperso en alguno de los 23 cromosomas, constituyendo quizá menos de la diezmilésima
parte del mismo. Aun cuando hoy día conocemos la secuencia de miles de genes
humanos, fruto del esfuerzo de muchos laboratorios de todo el mundo, el aislamiento
de ciertos genes clave sigue ocupando los titulares de revistas científicas.
Para comprender la admiración que inspira la culminación de una de estas empresas,
revisaremos una serie de procedimientos que se han diseñado para el aislamiento
de genes.
DIVERSOS NIVELES DE COMPLEJIDAD
Como se mencionó, los organismos unicelulares, los mícroorganismos, contienen cantidades mucho menores de material genético que los organismos superiores. Esto no impide que constituyan un grupo extremadamente diverso entre los seres vivos. Existe, pues, una enorme riqueza en los genes de estos organismos que se han adaptado a vivir en los más variados y extremosos ambientes. El interés de los científicos por el mundo microbiano mantendrá un paso acelerado en la búsqueda del conocimiento sobre las características de sus genes y su regulación. Adicionalmente, dada su simplicidad relativa, estos organismos constituyen excelentes modelos para estudiar la forma como los genes orquestan la actividad de las células: las bacterias usualmente tienen genomas con menos de cinco o 10 millones de pares de bases; muy simples si las comparamos con el genoma de un vertebrado, de más de mil millones de pares de bases.
Pasemos ahora a tratar un aspecto quizá poco conocido respecto a la ciencia biológica experimental. Se dice que la diferencia entre un ingeniero y un científico es que el primero resuelve los problemas que necesitan ser resueltos, mientras que el segundo, aquellos que pueden ser resueltos. En su búsqueda de conocimiento, el científico requiere seleccionar preguntas que sean abordables. El conocimiento se va construyendo paso por paso, de manera creciente, por lo que hay preguntas que no pueden ser resueltas en tanto no se tengan fundamentos previos. Desde luego, siempre estamos tironeados por dos fuerzas: las del interés por resolver preguntas que nos son cercanas (porque atañen a la naturaleza humana o a las enfermedades que nos aquejan, por ejemplo), y las de la curiosidad por resolver problemas fundamentales que sabemos que se deben rendir pronto con las herramientas y conocimientos de los que ya disponemos. Esto hace que los proyectos científicos se dividan en básicos y aplicados. En realidad, cada día están más cercanos los grupos que cultivan ambas modalidades: incluso muchos científicos abordan tanto problemas básicos como aplicados. Los proyectos de investigación básica formulan preguntas fundamentales, y deben diseñar los sistemas experimentales que permitan resolverlas. En el curso de la historia de la ciencia biológica, se han desarrollado "modelos" que son particularmente atractivos para responder ciertas preguntas. Así, por ejemplo, Mendel estudiaba las leyes fundamentales de la genética con la planta de chícharo: él podía distinguir características determinadas por los genes con gran facilidad, los chícharos eran lisos o rugosos, amarillos o verdes. En tiempos más recientes se han ido escogiendo otros modelos, cada uno con atractivos particulares.
En el nivel más simple se estudian las bacterias y sus virus. La bacteria favorita, cuyo estudio estableció el desarrollo de la biología molecular, es Escherichia coli, el bacilo del colon humano. Las variedades originalmente estudiadas ni siquiera causan enfermedades ni son particularmente benéficas para el hombre. Su atractivo deriva de su relativa simplicidad y de que se reproducen a gran velocidad, duplicándose cada 20 minutos. En el siguiente nivel se encuentran otros organismos unicelulares: las levaduras. Aquí se pueden encontrar fenómenos distintos, propios de organismos más complejos. Las levaduras son organismos eucariontes, por lo que su organización genética es mucho más cercana a la de plantas y animales que a la de las bacterias. Continuando en la escala ascendente de complejidad encontramos otro organismo modelo, un gusano llamado Caenorhabditis elegans. ¿Por qué escoger este organismo como modelo? Nuevamente, no es patógeno ni resulta benéfico. La razón se debe a que es un organismo pluricelular en el que se pueden estudiar fenómenos de diferenciación o especialización de células para crear tejidos y órganos, aunque todos ellos muy simples: cada uno de estos gusanitos está constituido por 1090 células exactamente. El genoma de este organismo está estudiándose intensamente y probablemente será el primer genoma de un organismo pluricelular del que conozcamos su secuencia completa. En niveles sucesivos de complejidad existe una planta modelo, Aratidopsis thaliana; la mosca de la fruta (Drosophila sp.) y el ratón (Mus musculus). Lo que aprendemos de estos organismos modelo es de incalculable valor para poder enfrentar los problemas de estudio y manejo de especies de importancia aplicada. Dada la asombrosa similitud de unos organismos y otros, a nivel de sus moléculas fundamentales, los genes que se aíslan del ratón, de la mosca de la fruta, y hasta de las bacterias, nos proporcionan mucha información de nuestros propios genes, o de los del trigo y el maíz.
En las siguientes secciones se describen los diversos enfoques que se han desarrollado para estudiar los genes de los diversos organismos, y se irá viendo cómo las técnicas que ha sido necesario implementar, responden precisamente a sus diferentes niveles de complejidad.
AISLAMIENTO DE GENES POR COMPLEMENTACIÓN
Los primeros genes microbianos fueron aislados mediante el principio de la complementación. Este procedimiento se fundamenta en el trabajo previo de los genetistas que, desde mucho tiempo atrás, habían caracterizado indirectamente a los genes. El trabajo clásico en genética microbiana implicaba el aislamiento y caracterización de bacterias mutantes, es decir, variantes que se generan espontáneamente o por un tratamiento químico o físico. Por ejemplo, una bacteria mutante puede haber perdido la capacidad de alimentarse con cierta sustancia, digamos el azúcar galactosa. Esto significa que algún gene relacionado con el proceso de asimilación de la galactosa está alterado. La genética clásica operaba con la convicción de que había habido un cambio en algún lugar del cromosoma bacteriano, precisamente donde se localizaba un gene (una entidad abstracta, para el caso) que debería codificar probablemente para una enzima, que quizá era responsable de catalizar la conversión de la galactosa en otra sustancia, más adelante en la cadena de asimilación. Desde luego que mediante pruebas indirectas se llegaba a deducir una gran cantidad de información alrededor de los genes, pero nada podía compararse a la posibilidad de observar directamente la secuencia del gene de interés. ¿Qué podríamos hacer para aislar este gene? Una vez que se dispone de las técnicas de clonación molecular, el proceso es conceptualmente sencillo.
Primero se requiere crear un conjunto de clonas que contengan segmentos de
un tamaño adecuado. Lo que se hace es someter una preparación del ADN
total de la bacteria en cuestión (de la cepa silvestre que contiene
el gene normal que nos interesa) a la acción de alguna enzima de restricción.
La reacción se controla para generar segmentos de unos 5 a 10 mil pares de bases,
cada uno capaz de contener unos cuantos genes. Esta colección de fragmentos
se liga a un vector de clonación (véase el recuadro II.2) y se introduce a células
de la cepa mutante (la que era incapaz de crecer en galactosa). Si colocamos
algunos miles de células así transformadas en una caja con medio nutritivo (claro,
donde el nutrimento sea galactosa), es probable que crezca alguna de ellas:
la que recibió el segmento que contenía el gene funcional; correspondiente al
gene mutante. Este gene ya no es más una entelequia. Se encuentra en un segmento
pequeño, insertado en un plásmido del que se pueden preparar grandes cantidades.
Este gene ha sido aislado, o purificado.
En los albores del ADN recombinante, aun este método directo y simple adolecía de un buen número de dificultades técnicas. Desde que se disponía de la clona con el gene de interés, hasta que se determinaba su secuencia nucleotídica, podían pasar muchos meses. Hoy día, el aislamiento y secuenciación de un gene microbiano puede ser una tarea de unas cuantas semanas.
AISLAMIENTO DE GENES USANDO ADN SINTÉTICO
Si reflexionamos un momento sobre la técnica de complementación anteriormente descrita, observaremos que se requieren dos aspectos cruciales para utilizarla: debemos poder llevar a cabo una transformación (introducción estable de genes) del organismo en cuestión, y debemos ser capaces de hacer depender su crecimiento de la adquisición del gene de interés. Estas condiciones no ocurren, ni con mucho, en todos los casos. De hecho, la capacidad de transformar organismos diferentes a E.coli ha sido desarrollada paulatinamente en los últimos 15 años y, aun cuando esto ya sea posible para muchos organismos, las dificultades que representa y los bajos rendimientos obtenidos hacen poco viable el uso generalizado de este método en el aislamiento de genes.
Se requería, diseñar otras estrategias capaces de localizar los genes. Es claro
que, dado que el ADN de todos los organismos tiene la misma naturaleza
química, resulta en principio igual de simple hacer un banco o colección de
clonas con el ADN de uno u otro organismo. Una primera diferencia
estriba en que, mientras más complejo sea el organismo, más clonas necesitaremos
para representar su genoma o, dicho de otra manera, necesitaremos buscar en
muchas más clonas para tener una buena probabilidad de encontrar un determinado
gene. Una cuenta sencilla nos persuade rápidamente de las diferencias: si cada
clona hecha en un vector de donación simple contiene 5 000 pares de bases, necesitaremos
unas 1 000 clonas (o un poco más, por razones estadísticas) para cubrir cinco
millones de pares de bases, que es el tamaño aproximado de un genoma microbiano.
En cambio, para representar el genoma humano, necesitaríamos cerca de un millón
de clonas. Para paliar este problema se han desarrollado vectores de clonación,
que pueden incorporar cantidades mucho mayores de ADN, indispensables
para el estudio de genomas más grandes (véase el capítulo siguiente).
Una vez resuelto el problema de cómo obtener un número manejable de clonas,
¿cómo hacemos para distinguir cuál de ellas (digamos entre algunos miles) contiene
el gene que nos interesa? Una aproximación se apoya en varios conceptos que
ya hemos descrito. En primer lugar; sabemos que las proteínas son codificadas
por los genes, y que por mucho tiempo fueron más fáciles de purificar; en realidad,
es muy probable que nos interese aislar los genes que codifican para las proteínas
que hemos estudiado durante mucho tiempo. A partir de la secuencia de aminoácidos
de una proteína, se puede inferir la secuencia de ADN que la codifica
(aunque de manera aproximada, dada la "degeneración" del código genético). Utilizando
este conocimiento se pueden diseñar oligonucleótidos sintéticos cuya secuencia
sea complementaria al gene correspondiente. Aquí entra en juego la asombrosa
capacidad de asociación específica de las moléculas de ADN (descrita
en el capítulo I, "Ácidos nucleicos"). Así que, en principio, utilizando un
pequeño segmento de ADN sintético (digamos de unas 20 bases), podríamos
hacerlo hibridar con nuestro conjunto de clonas y detectar su asociación específica
con el gene que codifica para la proteína de la cual inferimos su secuencia
(véase el recuadro III.1).
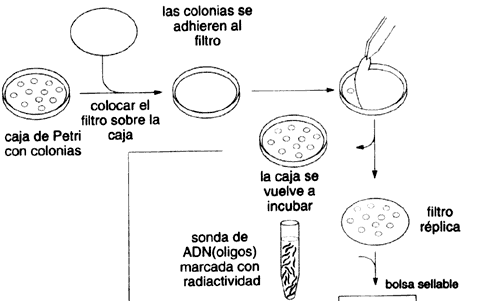 /
/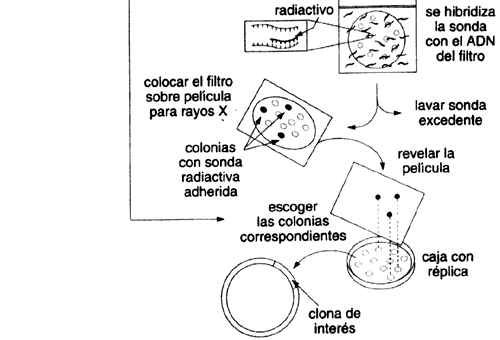
Esto se ha logrado para un gran número de genes.
En la actualidad, el uso de oligonucleótidos sintéticos se ha hecho muy complejo. Muchos genes se aíslan utilizando variantes de la técnica básica mencionada. La acumulación de datos sobre secuencia de genes de diversos organismos (véase el capítulo siguiente) permite utilizar un determinado gene de rata para aislar el gene correspondiente humano. En efecto, en muchos casos los genes de especies cercanas, por ejemplo mamíferos, son suficientemente parecidos para hibridizar mutuamente, aunque de manera imperfecta. Asimismo, el empleo de la reacción en cadena de polimerasa permite, en muchos casos, obviar inclusive el paso de obtener una biblioteca de genes. ¡Los genes pueden aislarse, en ocasiones, simplemente amplificándolos directamente a partir de una muestra mínima de material biológico!
AISLAMIENTO DE GENES UTILIZANDO ANTICUERPOS
Hemos descrito ya dos métodos para aislar genes. Quedan todavía muchos casos en los que las condiciones no son favorables para utilizarlos. Por ejemplo, hay ocasiones en las que la proteína cuyo gene correspondiente queremos aislar no se puede purificar en gran cantidad. Además, los métodos para determinar la secuencia de aminoácidos de una proteína son bastante laboriosos. Afortunadamente, el sistema inmunológico nos permite utilizar otro fenómeno de reconocimiento molecular para localizar genes interesantes.
Desde hace muchos años, los investigadores del campo de la inmunología han utilizado animales de laboratorio para obtener anticuerpos específicos contra sustancias de interés. Las proteínas, en particular; cuando son extrañas a un animal, inducen en éste la producción de anticuerpos. Estas moléculas son, a su vez, proteínas con características muy interesantes (véase el capítulo siguiente). Baste decir; por el momento, que los anticuerpos pueden ser usados como reactivos que reconocen, en medio de mezclas complejas, las sustancias específicas que indujeron su producción. Imaginemos que inyectamos una proteína de interés en un conejo. A partir del suero sanguíneo de este conejo podemos obtener anticuerpos dirigidos contra dicha proteína. Ahora podemos utilizar estos anticuerpos, de manera análoga a como se usaron los oligonucleótidos, para detectar en nuestro banco de donas aquella que contenga el gene que codifica para la proteína de interés.
En este punto quizá algún lector haya detectado un pequeño problema: el ADN
de todos los organismos es similar, pero la manera como éste se expresa para
formar proteínas específicas debe ser muy diferente; de hecho, de la diferencia
del control de la expresión de los genes deriva en gran parte la diferencia
entre unos organismos y otros. En efecto, la biblioteca genómica que requerimos
utilizar para hacer una "inmunobúsqueda", tiene que ser una biblioteca de expresión,
es decir, una en la que la donación de los genes se realice de tal manera que
haya señales propias de la célula recipiente (normalmente E.colí), que
induzcan la transcripción y la traducción del segmento de ADN
clonado.
AISLAMIENTO DE GENES UTILIZANDO SUS ARN MENSAJEROS
Llevamos tres métodos descritos para el aislamiento de genes. En principio, estas técnicas podrían ser usadas para obtener incluso genes humanos (o para el caso, de cualquier otro organismo superior). Nuevamente, las cosas son más complicadas de lo que parecen.
A finales de los años setenta, los trabajos pioneros de Phillip Sharp y Richard
Roberts sorprendieron a la comunidad científica con un asombroso descubrimiento.
Para describir en qué consistió lo insólito del descubrimiento, antes necesitamos
explicar ciertas características de estos experimentos, que ilustran algunos
de los métodos más útiles para aislar genes de organismos complejos. Sharp y
Roberts estaban a la caza de un gene de un vertebrado, que codifica para la
ovoalbúmina, la proteína más abundante del huevo de gallina. Establecer como
meta inicial un gene como éste tiene una importante razón de ser: un gene cuyo
producto es el mayoritario en un determinado tejido vivo resulta más fácil de
aislar. Esto se debe a que en el tejido respectivo se encuentran abundantes
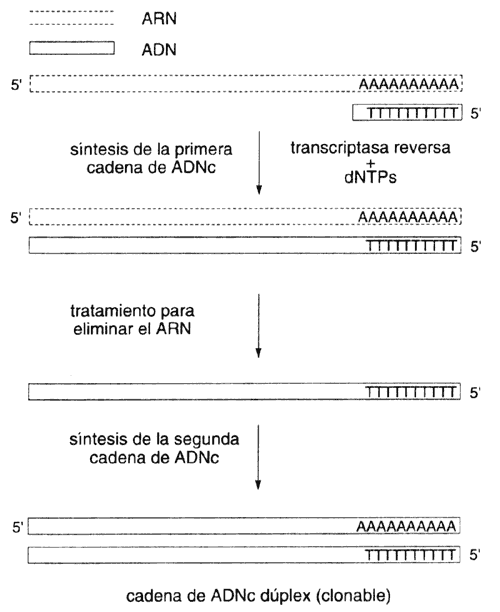
copias del gene en forma de ARN mensajero (véase el recuadro I.2).
De hecho, si se purifica ARN mensajero del oviducto de gallina,
la mayor parte de esta preparación estará constituida por el mensajero que codifica
para la ovoalbúmina. Surge sin embargo un problema: las técnicas de clonación
reclaman la disponibilidad de ADN, no de ARN, para
poder replicar y mantener moléculas recombinantes. Se hace necesario entonces
utilizar un procedimiento que convierta la información de ARN a
ADN. Es decir, que copie una hebra de ARN y la "transcriba",
de manera reversa hacia ADN. Esto es, en principio, posible: la
información (codificada en la secuencia) esta en la molécula de ARN.
Lo que se requiere es una enzima que realice la copia, pero que acepte como
molde al ARN, y como nucleótidos para incorporar a los del ADN.
Tal enzima existe en la naturaleza: en los retrovirus (variedad a la que pertenece
el virus del SIDA: véase el capítulo siguiente). Usando una preparación
que contenga esta enzima, la transcriptasa reversa, sobre el ARN,
se obtiene el llamado ADNc, o ADN complementario.
El ADNc puede ser clonado igual que cualquier otro ADN.
En el recuadro III.2 se ilustra el proceso de preparación de ADNc.
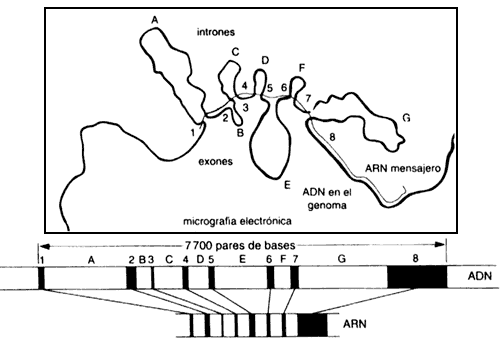
Ahora sí, estamos en condiciones de describir la sorpresa
encontrada por Sharp y Roberts. En efecto, ellos pudieron localizar clonas que
contenían ADN, complementario al mensajero de ovoalbúmina. Una
vez disponiendo de este material, pudieron utilizar la propiedad de hibridización
de los ácidos nucleicos para rastrear el gene original a partir de ADN,
aislado directamente de los cromosomas. Al comparar las donas de ADNc
y de ADN genómico se observó que éstas no coincidían exactamente.
¡El ADN genómico contenía segmentos adicionales de ADN,
al interior del gene! Estos segmentos se denominaron intrones (véase la figura
III.1), y subsecuentemente fueron encontrados en casi todos los genes de organismos
eucariontes. Este descubrimiento se adicionó a otro concepto ya firmemente establecido
por investigaciones anteriores: el genoma de organismos superiores contiene
mucho más ADN que el necesario para codificar las proteínas indispensables
para la función celular. De hecho, hasta el 95% del ADN de organismos
superiores está constituido por secuencias sin función aparente (véase el capítulo
siguiente).
|
Podemos comprender entonces que la complejidad de un genoma del ser humano
es mucho mayor que la de una bacteria o de una levadura. Aislar genes humanos
se parece mucho más a buscar una aguja en un pajar. Es por ello que se han desarrollado
muy diversos y complejos métodos, cuya descripción rebasa los propósitos de
este libro, para lograr este objetivo. Claramente, el método del ADNc
permite acceder a cualquier gene que se exprese abundantemente en algún tejido
en particular. El tamaño de una colección representativa de clonas de ADNc
será siempre mucho menor que el de una colección de clonas derivada directamente
del genoma.
En este punto quizá nos preguntemos: ¿algunos de los genes más interesantes e importantes no podrían ser de los que se expresan en pequeñas cantidades? La respuesta es rotundamente sí, pero aun este tipo de genes se han ido rindiendo a la tenacidad e imaginación de los investigadores. Un ejemplo muy interesante para ilustrar la cacería de un gene difícil es el caso de aquel cuyo defecto es responsable de la enfermedad llamada fibrosis quística, descrito en la siguiente sección.
AISLAMIENTO DE GENES RESPONSABLES DE ENFERMEDADES HEREDITARIAS
Quizá la mayoría de nosotros relacionamos el concepto de genética con atributos específicos de personas, animales o plantas, observables directamente. La herencia es evidente en el parecido de los hijos con sus padres, el color de los ojos, cierta marca de la piel, etc. De igual manera, existe un gran número de problemas de salud donde el componente hereditario es muy claro. La presencia de individuos enfermos se correlaciona de manera muy precisa, inclusive predecible, con determinadas familias. Es posible que muchos de nosotros identifiquemos como enfermedades hereditarias algunas de las más conocidas: la hemofilia, la enfermedad de Huntington, la anemia falciforme, la fenilcetonuria o la fibrosis quística. Muchas de las enfermedades hereditarias más conocidas pueden ser causadas por el defecto de un solo gene. Aunque las técnicas clásicas de la genética humana podrían haber establecido este hecho, la posibilidad de identificar el gene preciso, su producto proteico, y la lesión causante de la enfermedad, constituyen formidables retos que solo ha sido posible conquistar a partir del surgimiento del ADN recombinante. A la fecha se han identificado las funciones metabólicas defectuosas (es decir, la alteración de la actividad de alguna enzima) para unos 600 de los 3 500 defectos monogénicos descritos. De muchas de estas enfermedades ya se ha logrado aislar el gene responsable utilizando diversas técnicas, incluyendo las antes descritas. En esta sección explicaremos de manera más precisa lo que se requirió para obtener el gene responsable de la fibrosis quística.
Esta enfermedad ha sido claramente detallada desde hace más de 60 años. Su manifiestación clínica consiste en la producción de sudor muy salado, aunado a deficiencias respiratorias y digestivas. Esta enfermedad se encuentra con bastante frecuencia en ciertas poblaciones humanas, por ejemplo del norte de Europa o entre los estadunidenses de raza negra. Se manifiesta como de caracter autosomal recesivo, lo que quiere decir que afecta por igual a hombres y mujeres, y que se requiere tener los dos genes defectuosos (el paterno y el materno) para que ocurra la enfermedad. En las poblaciones afectadas se puede presentar en uno de cada 25 mil recién nacidos. ¡El gene defectuoso llega a estar en uno de cada 25 individuos! De manera similar al caso de muchas otras enfermedades, el tratamiento de la fibrosis quística consiste en paliar; en la medida de lo posible, la problemática asociada. Así, mediante un cuidadoso seguimiento de la dieta, la exploración del tórax, y otras medidas, se ha podido elevar la calidad de vida de los enfermos. Es claro, sin embargo, que para poder atacar mejor la enfermedad sería extremadamente útil conocer su causa última, a nivel molecular. Disponer del gene permitiría, además, identificar fácilmente a los portadores asintomáticos, es decir; a los que tienen sólo un gene defectuoso (en el capítulo V se hace una descripción sobre el diagnóstico genético).
Para el caso de otras enfermedades hereditarias, se ha podido recurrir al conocimiento
de la función precisa afectada y así identificar sistemas que expresan abundantemente
el gene en cuestión, inclusive en otros animales. A partir de estos sistemas
es posible obtener ADNc y, eventualmente, aislar el gene. Desafortunadamente,
en el caso de la fibrosis quística no existía ninguna forma de enriquecer el
ARN mensajero correspondiente: no se había logrado identificar
la función metabólica afectada. Un numeroso conjunto de investigadores en varios
países se dieron a la tarea de aislar el gene mediante la técnica de clonación
posicional. El primer paso en esta técnica requiere un análisis de asociación
entre marcadores genéticos previamente establecidos y el gene defectuoso. El
trabajo acumulado de muchos años ha permitido construir un mapa más o menos
grueso de diversas marcas, existentes en los cromosomas humanos. Estos mapas
se han ido refinando y complicando al utilizar técnicas de ADN
recombinante y forman una importante base para los esfuerzos que desembocarán
finalmente en la secuenciación completa del genoma humano (véase el capítulo
V). Mientras este objetivo no se haya logrado, se requiere utilizar la información
fragmentaria disponible para identificar genes específicos de gran interés.
El análisis de asociación se lleva a cabo utilizando muestras de ADN
de numerosos pacientes afectados por la fibrosis quística, así como de sus familiares.
Se puede inferir que aquellos marcadores que se heredan simultáneamente con
la fibrosis quística están asociados físicamente con ésta (es decir; en el mismo
cromosoma y cerca del gene). Esta asociación física indicó que el gene de la
fibrosis quística se encontraba en el brazo largo del cromosoma 7, entre los
marcadores denominados MET y D7S8. La tenaz y laboriosa búsqueda de varios años
empezaba a rendir frutos. La aguja ya no se encontraba en un pajar; sólo en
una carretilla de paja: ¡los marcadores identificaban un segmento de cromosoma
de alrededor de un millón y medio de pares de bases Este segmento tiene menos
del 1% de la longitud del cromosoma 7, pero todavía es demasiado largo; en él
caben muchos genes y mucho ADN espaciador (podemos notar que un
segmento de este tamaño es equivalente a un tercio del genoma de una bacteria
como E.coli). En pasos subsiguientes se identificaron sistemáticamente
clonas pertenecientes a esta región del cromosoma 7. Mediante ingeniosas técnicas
denominadas saltos y caminados cromosomales, después de varios
meses de intenso trabajo se logró identificar el gene. En el proceso también
fue necesario emplear ADN de bovino, ratones, cuyos y pollos, donde
se infería, con base en criterios evolutivos, que debía existir un gene similar,
pero no sus secuencias adyacentes. Finalmente, se solidificó la inferencia de
que el gene identificado era el que se buscaba al localizar una clona de
ADNc, obtenida de glándulas sudoríparas, que hibridizaba con la región
definida mediante el análisis posicional. El gene de la fibrosis quística se
encuentra distribuido en 250,000 pares de bases, constituido por 24 exones y
codifica para una proteína de 1480 aminoácidos.
Esta notable muestra de la investigación genética molecular moderna nos permitió ejemplificar los procedimientos desarrollados para lograr el aislamiento de genes particularmente elusivos. En capítulos subsiguientes describiremos algunas de las muchas cosas que pueden hacerse cuando se dispone de genes aislados, incluyendo los nuevos conocimientos y alternativas posibles para la terapia de la fibrosis quística.